
Introduction to MapReduce for .NET Developers
The basic model for MapReduce derives from the map and reduce concept in functional languages like Lisp.
In Lisp, a map takes as input a function and a sequence of values and applies the function to each value in the sequence.
A reduce takes as input a sequence of elements and combines all the elements using a binary operation (for example, it can use “+” to sum all the elements in the sequence).
MapReduce, inspired by these concepts, was developed as a method for writing processing algorithms for large amounts of raw data. The amount of data is so large that it can’t be stored on a single machine and must be distributed across many machines in order to be processed in a reasonable time. In systems with such data distribution, the traditional central processing algorithms are useless as just getting the data to the centralized CPU running the algorithm implies huge network costs and months (!) spent on transferring data from the distributed machines.
Therefore, processing such massive scales of distributed data implies the need for parallel computing allowing us to run the required computation “close” to where the data is located.
MapReduce is an abstraction that allows engineers to write such processing algorithms in a way that is easy to parallelize while hiding the complexities of parallelization, data distribution, fault tolerance etc.
This value proposition for MapReduce is outlined in a Google research paper on the topic:
MapReduce is a programming model and an associated implementation for processing and generating large data sets. Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key. Many real world tasks are expressible in this model, as shown in the paper.
Programs written in this functional style are automatically parallelized and executed on a large cluster of commodity machines. The run-time system takes care of the details of partitioning the input data, scheduling the program’s execution across a set of machines, handling machine failures, and managing the required inter-machine communication. This allows programmers without any experience with parallel and distributed systems to easily utilize the resources of a large distributed system.
Our implementation of MapReduce runs on a large cluster of commodity machines and is highly scalable: a typical MapReduce computation processes many terabytes of data on thousands of machines. Programmers find the system easy to use: hundreds of MapReduce programs have been implemented and upwards of one thousand MapReduce jobs are executed on Google’s clusters every day.
The MapReduce Programming Model #
As explained earlier, the purpose of MapReduce is to abstract parallel algorithms into a map and reduce functions that can then be executed on a large scale distributed system. In order to understand this concept better lets look at a concrete map reduce example — consider the problem of counting the number of occurrences of each word in a large collection of documents:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, “1”); *
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));*
The map function goes over the document text and emits each word with an associated value of “1”.
The reduce functions sums together all the values for each word producing the number of occurrences for that word as a result.
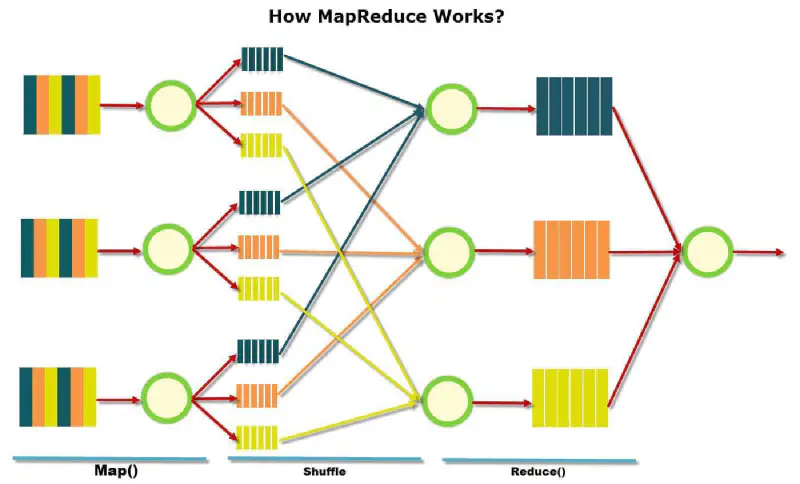
First we go through the mapping phase where we go over the input data and create intermediate values as follows:
Records from the data source (lines out of files, rows of a database, etc.) are fed into the map function as <key,value> pairs.For example: <filename, file content>
The map function produces one or more intermediate values along with an output key from the input
After the mapping phase is over, we go through the reduce phase to process the intermediate values:
After the map phase is over, all the intermediate values for a given output key are combined together into a list and fed to the reduce function.
The reduce function combines those intermediate values into one or more final values for that same output key
Notice that both the map and the reduce functions run on independent set of input data. Each run of the map function process its own data source and each run of the reduce function processes the values of a different intermediate key.
Therefore both phases can be parallelized with the only bottleneck being the fact that the map phase has to finish for the reduce phase to start.
The underlying system running these method is in takes care of:
Initialize a set of workers that can run tasks — map or reduce functions.
Take the input data (in our case, lots of document filenames) and send them to the workers to map
Streamline values emitted by map function to the worker (or workers) doing the reduce. Note that we don’t have to wait for a certain map run to finish going over the entire file in order to start sending its emitted values to the reducer, so that the system can prepare the data for the reducer while the map function is running (In Hadoop — send the map values to the reducer node based on grouping key).
Handle errors — support a reliable, fault tolerant process as workers may fail, network can crush preventing workers from communicating results, etc.
Provides status and monitoring tools.
A Naive Implementation in C #
Lets see how we can build naive MapReduce implementation in C#. First, we define a generic class to manage our Map-Reduce process:
public class NaiveMapReduceProgram<K1, V1, K2, V2, V3>
The generic types are used the following way:
(K1, V1) — key-value types for the input data
(K2, V2) — key value types for the intermediate results (results of our Map function)
V3 — The type of the result for the entire Map-Reduce process
Next, we’ll define the delegates of our Map and Reduce functions:
public delegate IEnumerable<KeyValuePair<K2, V2>> MapFunction(K1 key, V1 value);
public delegate IEnumerable<V3> ReduceFunction(K2 key, IEnumerable<V2> values);
private MapFunction _map;
private ReduceFunction _reduce;
public NaiveMapReduceProgram(MapFunction mapFunction, ReduceFunction reduceFunction) {
_map = mapFunction;
_reduce = reduceFunction;
}
(Yes, I realize I could use .NET’s Func<T1,T2,TResult> instead but that would just result in horribly long ugly code…)
Now for the actual program execution. The execution flow is as follows: We take the input values, pass them through the map function to get intermediate values, we group those values by key and pass them to the reduce function to get result values.
So first, lets look at the mapping step:
private IEnumerable<KeyValuePair<K2, V2>> Map(IEnumerable<KeyValuePair<K1, V1>> input) {
var q = from pair in input
from mapped in _map(pair.Key, pair.Value)
select mapped;
return q;
}
Now after we got the mapped intermediate values we want to reduce them. The Reduce function expects a key and all its mapped values as input so to do that efficiently we want to group the intermediate values by key first and then call the Reduce function for each key.
The output of this process is a V3 value for each of the intermediate K2 keys:
private IEnumerable<KeyValuePair<K2, V3>> Reduce(IEnumerable<KeyValuePair<K2, V2>> intermediateValues) {
// First, group intermediate values by key
var groups = from pair in intermediateValues
group pair.Value by pair.Key into g
select g;
// Reduce on each group
var reduced = from g in groups
let k2 = g.Key
from reducedValue in _reduce(k2, g)
select new KeyValuePair<K2, V3>(k2, reducedValue);
return reduced;
}
Now that we have the steps code the execution itself is simply defined as Reduce(Map(input)) :
public IEnumerable<KeyValuePair<K2, V3>> Execute(IEnumerable<KeyValuePair<K1, V1>> input) {
return Reduce(Map(input));
}
The full source code and tests can be downloaded from here:
Map-Reduce Word Counting Sample — Revisited #
Lets go back to the word-counting pseudo code and write it in C#.
The following Map function gets a key and a text value and emits a <word, 1> key-pair for each word in the text:
public IList<KeyValuePair<string, int>> MapFromMem(string key, string value) {
List<KeyValuePair<string, int>> result = new List<KeyValuePair<string, int>>();
foreach (var word in value.Split(' ')) {
result.Add(new KeyValuePair<string, int>(word, 1));
}
return result;
}
Having calculated a <word, 1> key-pair for each input source, we can group the results by the word and then our Reduce function can sum the values (which are 1 in this case) for each word:
public IEnumerable<int> Reduce(string key, IEnumerable<int> values) {
int sum = 0;
foreach (int value in values) {
sum += value;
}
return new int[1] { sum };
}
Our program code looks like this:
MapReduceProgram<string, string, string, int, int> master = new MapReduceProgram<string, string, string, int, int>(MapFromMem, Reduce);
var result = master.Execute(inputData).ToDictionary(key => key.Key, v => v.Value);
The result dictionary contains a <word, number-of-occurrences> pairs.
Other Examples #
Distributed LINQ Queries. One of POCs I’m working on using the above naive, LINQ-based implementation, is running a distributed LINQ query. Imagine you have a system where raw data is distributed across several SQL Servers. We can have our map function run a LINQ-to-SQL query on multiple DataContexts in parallel (the value input for the map function — V1 — can be a DataContext) and then reduce it to a single result set. This is probably a naive\simplified implementation of what the guys at Microsoft’s Dryad team are doing.
Count URL Visits. Consider you have several web servers and you want to produce the amount of visits for each page on your site. You can produce pretty much the same way the word-counting example works. The map function parses a log file and produce a <URL, 1> intermediate value. The reduce function then sums the values for each URL and emits <URL, number of visits>
Distributed Grep. You can run a grep search on a large amount of files by having the map function emits a line if it matches a given pattern. The reduce function in this case is just an identity function that copies the supplied intermediate data to the output.
Map-Reduce in the Real World #
The real complexity and sophistication in MapReduce is in the underlying system takes care of running and managing the execution of MapReduce jobs. Real world MapReduce implementations, like Google’s system, Hadoop or Dryad have to go beyond the naive implementation shown here and take care of things like resource monitoring, reliability and fault tolerance (for example, handle cases where nodes running map\reduce jobs crush, or go offline due to network problems).
The following resources are worth checking out:
Google Code University — Distributed Systems