
Scaling Your Analytics Schema Using Events Grammar

One of the most important aspects of building your own analytics system is how you store the data and expose it for querying. This post describes the challenges and approach taken when designing the analytics system for dapPulse (now monday.com) and later at Wondermall.
Problem Definition #
Most Analytics software out there lets you define events as an event_name coupled with a bag of data properties.
It doesn’t scale…
While this approach is simple and works very well for a small number of events, it simply doesn’t scale. Your events catalog can very quickly grow to a size where it’s very hard to keep track of all the different events and the description of the properties that describe them. Most companies usually resort to an external document describing the entire catalog. This document then needs to be maintained and updated whenever anyone adds or modifies an event. It rarely gets done…
Complex schemas
In most systems, the properties we send with each event are widely different for each event. This means that the schema for saving such data is very sparse. You need lots of columns to fit the needs of every event in the system, where each event only uses a small subset of these columns.
There are 2 ways this is implemented:
“Fat Table” — Lots of specific columns where each event uses the ones that fit its needs (a cart_id column is useful for add_to_cart event but not for login event). This makes the schema extremely sparse where every event uses only a small subset of columns — hard to manage and query. You can see an example of such a schema here.
Generic Columns (like value1, value, …) optimize the number of columns used but strip away the information as to what the value represent. value1 can be a Cart id for one event, and Product id for another*. You can’t know what the value represents just from looking at the data.*
Usually, both are used. We have specific columns for all the values we know we’ll need, and we keep a number of generic ones as extras just in case we need to send something new that we didn’t think of beforehand. The result is a very complex sparse schema that is hard to understand, query, maintain and grow.
Discoverability
Having such a large complex schema makes looking at the data hard. Suppose we look at an event row. We know what kind of event it is by the event’s name. But then we have tens of other columns to look at. Some are relevant, some are not…. some are generic — who knows what is the value in value1 column stands for?
This kind of schema makes it extremely hard to just browse data and know what you’re looking at without the help of an external (usually outdated) event catalog spec document.
Building an Event Grammar #
With the above in mind, when thinking of designing a new analytics system I wanted to build something different that tackles the issues Ive experienced in previous systems. I’ve read about the “event grammar” approach on the Snowplow blog (here and here) and immediately liked it as it seemed to solve all my woes.
Modeling Events
Basically, in the “event grammar” approach we model our event data the same way we model an English sentence:
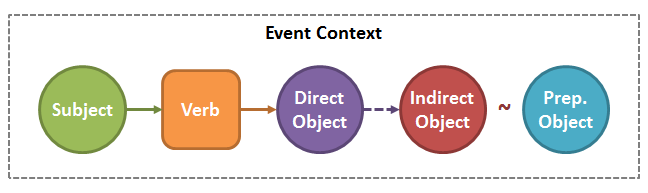
To translate this to an actual schema, we describe each object — Subject, Direct\Indirect\Prepositional — using 3 fields:
- type — the object’s type (for ex: Store)
- key — a unique identifier identifying the specific object instance we’re referring (For ex: a store database id)
- display (optional) — A nice display string for the objected we’re referring to.
For example, the event User added Product to Cart would be:
User<123, "John D."> add Product<"a12", "Scissors"> to Cart<212>
Our Subject is “John D.” — a User who’s id is 123.
The verb is add.
Our Direct Object is Scissors — a Product with id a12.
Our Indirect Object is a Cart who’s id is 212.
It’s Simple!
The grammar schema uses few generic columns (3 X 4 possible objects) generic columns — enough of them to express almost anything you need — while being able to look at the data and know what it stands for.
Since we’re using generic columns — the schema is not as sparse. Most events will have a subject, verb, direct_object sand 2 more optional objects. It makes it easier to look and query the data then going over a list of more than 50 columns…
When you look at an object, like User<123, “John D.”> it’s very clear what you’re looking at — a User object who’s id is 123.
Discoverable
Since we only have a limited set of generic objects we use, and a standard for how an object looks (has a key, a type, and display values) it’s pretty easy to explore the data to find out you need using GROUP BY queries.
For example, the following query will result in a list of all the verbs and direct objects a User interacts with:
SELECT
verb, direct_object.type as direct
FROM
...
WHERE
subject.type = "User"
GROUP BY
verb, direct_object.type
ORDER BY verb ASC
This could be something like:
add, Product
add, WhislistItem
click, Button
create, Order
create, Review
share, Product,
share, Review,
view, Screen
view, Product
view, Category
Logical vs. UI Event
When modeling an app’s events we usually get into the dilemma of logical events vs. behavioral.
To understand this dilemma lets say we’re modeling events for a mobile commerce app. We’ll probably need some sort of page view event for the different screens the user sees on the app:
User<123, "John D."> viewed Screen<"storefront">
Now, what happens when a user views a product screen?
User<123, "John D."> viewed Screen<"product_v1">
**with** Product<"a12", "Scissors">
Note that we may have several screens where the user can see a product (for example, if we’re AB testing the product screen)
User<123, "John D."> viewed Screen<"product_v1">
with Product<"a12", "Scissors">
User<123, "John D."> clicked Button<"add_to_cart">
on Screen<"product_v1">
User<123, "John D."> clicked Button<"checkout">
User<123, "John D."> viewed Screen<"checkout">
User<123, "John D."> viewed Screen<"confirmOrder"> ...
User<123, "John D."> viewed Screen<"orderConfirmation"> of Order<12>
All these events describe behaviors of the user in the app. But what if I want to know, for example, which products a user last viewed? I’ll have to make a complex query that assumes I know all the possibilities for a user to view a product (which screens are on our AB test etc):
SELECT
indirect_object.key
FROM
...
WHERE
subject.type = 'User' AND subject.key == '123' AND
direct_object.type = 'Screen' AND direct_object.key IN ('product_v1', 'product_v2', ...)
When asking these kind of questions I don’t and shouldn’t care about UI implementation details. This is where logical events come in:
User<123, "John D."> viewed Product<"a12", "Scissors">
User<123, "John D."> add Product<"a12", "Scissors"> to Cart<212>
User<123, "John D."> created Order<100>
And my query would be
SELECT
direct_object.key
FROM
...
WHERE
subject.type = 'User' AND subject.key == '123' AND
direct_object.type = 'Product'
Makes more sense right? Logical events are not tied to a specific app or implementation. A User, for example, can also view a Product from an email. In this case, we’ll use the context to know where event occurred (if we care)
We’ve found that it makes sense to send both logical and *behavioral events, *even though they seemed like duplicates at the beginning they’re both used in different contexts and queries.
The Full Schema (Using BigQuery) #
The full schema we’re using on BigQuery add a couple of more meta fields:
# big_query_dsl.py
__author__ = 'ekampf'
class FieldTypes(object):
integer = 'INTEGER'
float = 'FLOAT'
string = 'STRING'
record = 'RECORD'
ts = 'TIMESTAMP'
class FieldMode(object):
nullable = 'NULLABLE'
required = 'REQUIRED'
repeated = 'REPEATED'
def Field(name, column_type, description=None, mode=None, fields=None):
field = dict(name=name, type=column_type)
if description:
field['description'] = description
if mode:
field['mode'] = mode
if fields:
field['fields'] = fields
return field
def StringField(name, mode=None, description=None):
return Field(name, FieldTypes.string, mode=mode, description=description)
def FloatField(name, mode=None, description=None):
return Field(name, FieldTypes.float, mode=mode, description=description)
def IntField(name, mode=None, description=None):
return Field(name, FieldTypes.integer, mode=mode, description=description)
def TSField(name, mode=None, description=None):
return Field(name, FieldTypes.ts, mode=mode, description=description)
def RecordField(name, fields, mode=None, description=None):
return Field(name, FieldTypes.record, fields=fields, description=description, mode=mode)
# schema.py
import big_query_dsl
OBJECT_SCHEMA = [
StringField('key', description="The object's key/id", mode=FieldMode.required),
StringField('type', description="The object's type", mode=FieldMode.required),
StringField('display', description="The object's display name.", mode=FieldMode.nullable)
]
ANALYTICS_SCHEMA = [
TSField('timestamp'),
RecordField('subject', OBJECT_SCHEMA, description="This is the entity which is carrying out the action. Ex: '*Eran* wrote a letter'"),
StringField('verb', description="Describes the action being done. Ex:'UserX *wrote* a letter'"),
RecordField('direct_object', OBJECT_SCHEMA, description="The noun. The entity on which action is being done. Ex: 'Eran wrote *a letter*"),
RecordField('indirect_object', OBJECT_SCHEMA, description="The entity indirectly affected by the action. Ex: 'Eran wrote a letter *to Lior*'"),
RecordField('prepositional_object', OBJECT_SCHEMA, description="An object introduced by a preposition (in, for, of etc), but not the direct or indirect object. Ex: 'Eran put a letter *in an envelope*'"),
StringField('context', description="JSON providing extra event-specific data"),
# meta about event collection
StringField('tracker_version', description="Version string of the software sending events from client."),
StringField('collection_version', description="Version string of server-side receiving frontend."),
]
Basically, we have our grammar fields: subject, verb, direct_object, indirect_object, prepositional_object.
We’ve also added:
timestamp — obviously we need to know when the event occurred.
context — any property sent that doesn’t match one of the schema fields is moved into this JSON value. This allows us to send (and later query) extra data with the event that didn’t fit the other fields.
tracker_version & collection_version — We keep the version of the client library that sent the event and the server’s code that processed it for bug tracking purposes.
If you have other values that you know you’re going to send with most of the events you better add it as a schema field too. Some examples of such fields could be session_id, tenant_id (for multi-tenant SaaS apps) etc.